

Tim shares the discovery process of a recent Ghostscript bug, and lessons learned.
Ghostscript is a rendering engine for Postscript and PDF content developed by Artifex Software, commonly used to convert PDF and Postscript documents in to images for preview, thumbnailing and printing purposes.
As this is the only full-featured Open Source Postscript renderer, if you see a thumbnail for a Postscript document on a Linux desktop, it was probably created by Ghostscript. It is also used for full-quality rendering of documents for many PDF viewers, including popular viewers on Android, and is licenced by a number of large companies like Google for rendering in the cloud. In short, it’s probably in more places than you would think. While the majority of these users are likely to be using the AGPL edition, a commercial distribution is also available for embedding in non open-source products.
This post will hopefully make the impact of this issue clearer, and encourage people to patch this issue themselves if required. Despite the bug now being in the public eye, a patch available, and the embargo on it having elapsed, there is no Windows package available and not all Linux distributions have a patch available. We feel there may be some confusion about what this bug involves, what is likely to be vulnerable, and hope this post will clarify.
Summary
Insomnia Security found a buffer length calculation flaw in a non-standard Postscript operator in Ghostscript, which allows the creation of a 4GB “string” reference overlapping with other memory structures. This was introduced in Ghostscript 9.50 and is present in the latest official 9.52 release. By reading and writing through this string reference, heap content can be directly manipulated, resulting in arbitrary read/write of memory.
By reading and writing only data memory (i.e. no direct injection of shellcode), Insomnia Security found the sandbox can be reliably disabled, and dangerous Postscript functionality made available. This includes arbitrary file reading and writing, as well as OS command execution in environments with this enabled (Linux, some Windows environments). Exploitation using standard memory corruption techniques would also be viable.
Postscript Language
What’s not at all obvious from looking at a Postscript document is that Postscript in in fact a fully featured programming language. It was developed by Adobe Systems between 1982 and 1984, and includes all of the features required for complex logic. It has a relatively simple execution environment, and is often directly interpreted by printers and other lower-end devices.
Postscript takes the form of a stack-based language, where values are pushed on to a stack, then popped off it by later operations. Postscript code to add 1 and 2 might look like:
1 2 add
To draw a circle, you might use the code:
100 500 100 0 360 arc closepath
stroke
This defines an "arc" from 0 to 360 degrees, at a radius of 100 from the point (100, 500), creates a closed path object, then draws it:

The language specification includes all the standard mathematical and looping constructs, as well as drawing operations. By using a fully featured programming language, repeated designs and patterns can be generated without having to actually repeat their content. The document can also be produced at multiple scales and resolutions depending on the capabilities of the rendering device.
The program which interprets this code and produces a rendered page is the Postscript interpreter. The Ghostscript interpreter implements the Adobe specifications, and provides a number of standard and non-standard operators.
The Sandbox
Ghostscript includes a significant amount of functionality which is dangerous to allow untrusted Postscript code to execute. In particular, the %pipe% device allows execution of arbitrary operating system commands, and external files may be read and written as part of trusted Postscript rendering. To prevent these from being exploited, Ghostscript applies a “sandbox” environment when the –SAFER option is passed, and recently by default.
This sandbox used to exist purely inside the Postscript environment, by deleting all the dangerous operations or forcing them to check whether the interpreter is operating in “SAFER” mode. This was bypassed in a series of ways by Tavis Ormandy in 2018, in particular around the Postscript operations to save and restore previous states. For those who follow bug disclosures, this doesn’t mean terribly much, as Tavis seems to find such bugs in all sorts of things (e.g. breaching systems through their AV software). However, he also mentioned at the time to expect further bugs, and such comments are generally to be relied upon.
As a result of these issues, Artifex implemented a new sandbox mode called the Path Control Sandbox. This allows file read/write operations to be locked down to a fixed list of directories, and command execution disabled. This sandbox exists in the compiled interpreter, not in the interpreted Postscript code, so is unaffected by saving/restoring state. Once enabled, it stays enabled for the lifetime of the interpreter (or at least it should…)
Discovery
So this all started with a client engagement, where very early in the process we noticed that the Ghostscript interpreter was in use, being used to create an image version of a document. While it expected a PDF, it accepted and rendered Postscript documents just fine.
Knowing that Ghostscript had a series of sandbox breakouts but very little else, we decided to fuzz the file input with American Fuzzy Lop (AFL). This is something that others are presumably doing all the time, but we had a 16 core server and a few weeks so thought this would at least give me an idea about whether this attack surface was still as fragile as it used to be, and what level of mitigation to recommend.
One Google search found another person’s test harness for Ghostscript (Thank you Nelson Elhage) which worked with minimal work out of the box. We fed it a set of half a dozen snippets of Postscript – even an empty file. The only thing we did differently, that others may not have tried, was doing a pattern search on the Ghostscript source code for the names of all operators (add, sub, etc) and feeding these in as a “dictionary”.
AFL works by changing the input until a new code path is executed. Postscript input is not well suited to this approach, because there are really no special command names or keywords as such, and all the system commands are a lookup in a “dictionary” object (hash table). As a result, these names aren’t readily discoverable by tracing code paths. Feeding them to AFL, each command in its own file in a dictionary directory, allows it to insert whole words at a time rather than discover them letter-by-letter, finding results a lot more effectively.
The result was surprising. Within a matter of hours, AFL produced a series of crashes around one particular operator – rsearch. In each of these cases, the file contained an expression like ()dup rsearch followed by some other stuff, which eventually resulted in a crash because it tried to access invalid memory addresses – a segmentation fault. The common thread was that one code snippet, which seemed to crash everything which used its results:
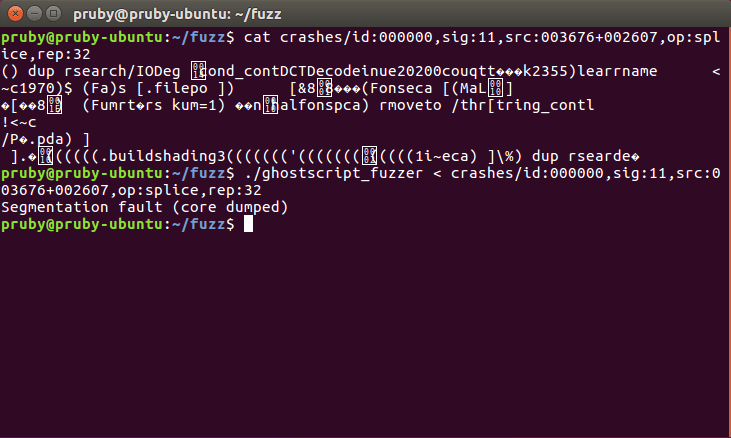
This affected a plain, compiled version from source, but interestingly did not affect the version installed with my OS. As it turns out, this was because of when the bug was introduced – this was a feature introduced relatively recently so affects only very recent feature releases of each Operating System, and those who get their packages directly from Artifex.
The Bug
The search operator in Postscript looks for a piece of text (string) inside another piece of text, breaking it down in to the bit before the match, the match result, the bit afterwards, and a flag to say whether or not it matched. The rsearch operator was created last year as a non-standard operator in Ghostscript to add a reverse-search, to find the last match for something rather than the first.
The snippet found by AFL was pushing an empty string on to the stack – the empty brackets (), copying the reference to this, resulting in a stack with two empty strings on it () (), then executing the reverse search. In other words, it was looking for an empty string in an empty string, starting from the end.
Unfortunately, they missed a boundary case where the empty string is searched. When searching for an empty string, this is defined as immediately succeeding – there’s nothing to look for so we jump straight to the end. However, the result needs to be divided in to the pre-match, match, and post-match values. Unfortunately the code assumed we’d looked at least once, and calculated the length of the post-match result incorrectly by subtracting one from zero – resulting in a wrap-around to the maximum value – 4,294,967,295.
This bug is an absolutely premium memory corruption flaw. No chance of failure – it happens every time. No need to deal with stack guards, etc – just read/write whatever you want to a massive segment of memory. This made it quite easy for someone who is not an experienced exploit writer (i.e. me) to exploit it.
Due to this underflow, this string had never been allocated and took up no actual space on the heap, but had a length which extended in to other heap memory. Attempting to read or write that memory at random addresses would go outside of memory bounds, hence all the crashes in the fuzzing. We could, however, store the reference to allow it to be used using this code fragment:
/memptr () dup rsearch pop pop pop def
Used in a more controlled way, this string object allows memory to be arbitrary read and written, byte-by-byte, for a large chunk of the heap. Strings in Postscript act like an array (list) of bytes. It starts in an unknown place, and allows us to read at an offset from this start point. To read a byte at offset 123, we would execute:
memptr 123 get
To write a zero at offset 123, we would execute:
memptr 123 0 put
This gives us all the control we need to read/write arbitrary memory following the pointer.
Out of the Window
While the above is interesting, it only lets us affect a fixed window of memory. This is likely to include much of the heap’s content, but not necessarily important structures like the global interpreter state, which could appear before the window and in an unknown place. To break out of the window, and get full control of everything, we wanted overlapping control of an object reference and its underlying memory representation as a string.
Postscript, like many languages, doesn’t copy data structures every time you pass them around. If we define a string then duplicate (dup) it, the whole thing isn’t copied:
(This is a test!)
dup
Instead, we end up with two references to the same string. If we change one, for example by writing a byte, it also changes the other:
(This is a test!) % Create a string
dup % Copy it
14 63 put % Modify the copy, consuming its stack entry in the process
= % Print out the original string record
The above will change one string then print the other copy, resulting in the message “This is a test?”. The stack is actually a list of reference types – ref_t in Ghostscript’s C code. Numbers like 1, 2, 3, etc are stored directly in the reference object and passed by value (i.e. can’t be changed from elsewhere), while objects like strings, arrays, and dictionaries are stored as references.
All ref_t objects on all platforms take up 128 bits. This is split in to a 64-bit header which contains the type, a length field, and a series of flags such as read-only, followed by a 64-bit “value” field, which contains either the value or a pointer to where it actually lives in memory.
To get my overlapping object and reference required some spraying, which we won’t go in to great detail on, but went like:
- Create a lot of numbers that will be recognisable (i.e. not occur randomly) in memory.
- Search the area of the heap we can read/write for
ref_tstructures matching this number. - Change one in to a different type (floating point number) by setting the type bits.
- Look through my many copies until we find a floating point number.
- Get a stable way of reading/writing the value in Ghostscript, and snip out the string section corresponding to its
ref_trepresentation in memory.
I’ll leave the details of that as an exercise for the reader.
The ability to change the raw ref_t object underlying a variable is a game changer. By setting this to a string type with a reasonable length, then setting its address anywhere in memory, we can read/write the structure we’re pointing to. By writing any object in to the variable we can read out the address where the actual data lives in memory.
Exploitation
So normally when we find a memory corruption exploit, we’d proceed to write some shellcode or maybe a ROP chain in to memory, corrupt some pointer address and force it to execute our code. However, modern OS protections like ASLR, DEP, stack protectors, etc make this extremely difficult in practice. While there are others in the office who would have the experience to make this approach work, I personally don’t, and decided try to exploit the bugs an easier way first!
My thoughts went like this:
This is a fully featured programming language right? It has the ability to execute arbitrary commands, read/write files, and all the things we want, disabled by a single flag in memory. Previous bugs for this platform have focussed on disabling the earlier version of the sandbox as a target, and despite the location of the sandbox having moved it still makes sense as an end-goal. We just have to find that byte.
The best place to start looking is the code which turns on the sandbox in the first place. Since Ghostscript is open source, we can find this in the code. The documentation says it’s turned on with the .activatepathcontrol operator, which a search reveals being registered here:
https://github.com/ArtifexSoftware/ghostpdl/blob/ghostscript-9.52/psi/zfile.c#L958
The function implementing this can be found here:
https://github.com/ArtifexSoftware/ghostpdl/blob/ghostscript-9.52/psi/zfile.c#L920
Which just calls the gs_activate_path_control function found here:
https://github.com/ArtifexSoftware/ghostpdl/blob/ghostscript-9.52/base/gslibctx.c#L912
This starts from a gs_memory_t object, retrieves the gs_lib_ctx field from that, retrieves the core field from that, and sets the path_control_active field on that to 1. So if we get a gs_memory_t object we can just follow this same process, writing a zero to unset the flag.
After looking at a lot of different Postscript types, there were references to a “memory” field on dictionaries:
https://github.com/ArtifexSoftware/ghostpdl/blob/ghostscript-9.52/psi/idict.h#L32
It turns out that dictionaries have a reference to the memory allocator gs_memory_t, presumably so that they can use it to allocate more memory to expand themselves if more keys are added. The entire dictionary structure consists of a series of ref_t entries, pointing on to further records.
By writing the system dictionary in to the variable its address will be stored in to the underlying ref_t. We then change this reference to be interpreted as a string of a reasonable length, and by reading that string we can extract pointers from the dictionary structure. Since the ref_t structure is a fixed size across all architectures, compilers and platforms, and fields are usually stored in order, the offset of the second half of the fifth ref_t reference should always be four times sixteen bytes (128 bits) plus 8 bytes (64 bits) – 72 bytes to get to the right offset.
Once we have that, we can create a string reference pointing at it, copy out the pointers, and write them back to our ref_t to follow the pointer on to the next structure.
When we compile C code, which is what is used to write Ghostscript, we lose all of the friendly names used for our structures. Instead, the compiler decides how to lay out the structure in memory according to its conventions, which vary across architectures and platforms. Each of these friendly names like “core” then gets turned in to an offset in the structure, like 80, which can be used directly in the compiled code.
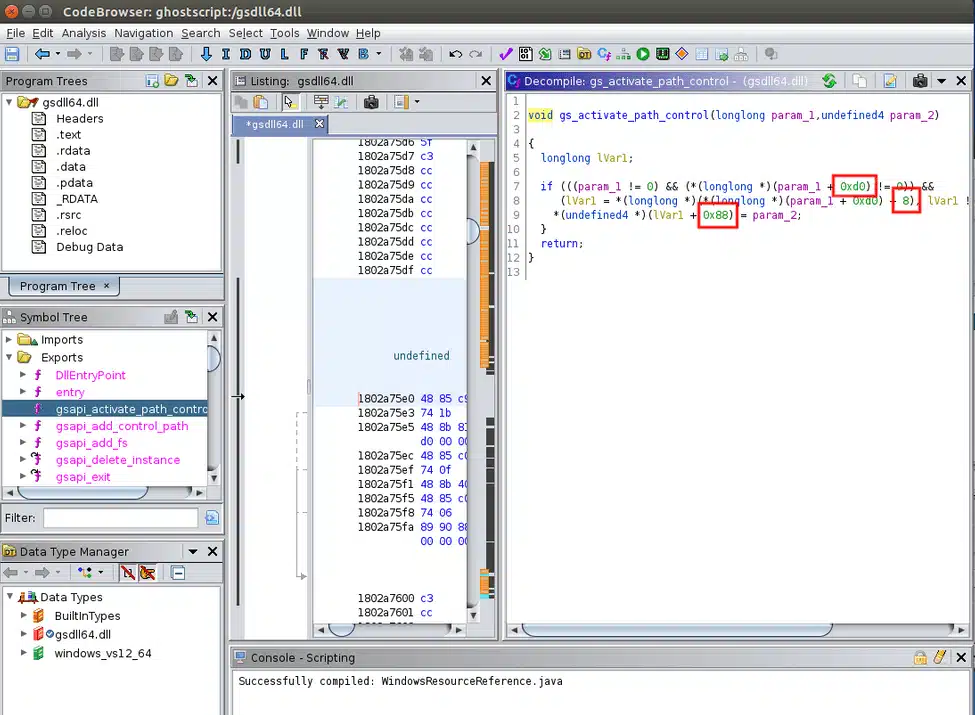
Each further step to pull out a field requires that we know the offset that a particular field lives within a structure. This varies between different architectures, and we were testing a different version, didn’t have a compiler set up for, so we needed to pull this out from a binary. We did this by running the official library version (in this case gsdll64.dll) through Ghidra, finding the gs_activate_path_control function, which is the only function called by the wrapper gsapi_activate_path_control exported as part of the API, and pulling out the offsets it was adding to the pointers in order, in this case 0xd0, 8, and 0x88:
Result
The end result of all of this was code that would disable the sandbox, after which we could go exploring, run commands and read/write files (which anyone who has exploited such bugs knows, usually ends in the same thing).
Conclusions
Despite efforts to improve sandboxing, there is still a very substantial attack surface in Postscript rendering, and running Ghostscript on fully untrusted input (e.g. external files) should be considered dangerous. There are substantial numbers of un-triaged crashes we found in days from a simple fuzzing run, though the one reported is the only one we know to be exploitable.
If you have a workload like this, don’t assume that the sandbox will be sufficient. Use further isolation, such as running under low-privileged user accounts, applying sandboxing, or even running on separate or ephemeral hosts entirely.
Don’t assume that just because a library like this is public that it’s receiving enough scrutiny such that all shallow bugs are fixed. This was a very shallow bug, exploitable with no need to deal with or evade mitigations such as ASLR and DEP, and which had been introduced around a year before we found it.
Timeline (NZT)
- 01 July 2020 – Bug identified on client engagement.
- 22 July 2020 – Client consent to begin responsible disclosure.
- 22 July 2020 – Vulnerability disclosed to Artifex Software bug tracker.
- 22 July 2020 – Artifex confirm vulnerability, produce draft patch.
- 23 July 2020 – CVE-2020-15900 assigned to vulnerability.
- 25 July 2020 – Patch released to public source control repository (commit
5d499272b95a6b890a1397e11d20937de000d31b). No warning given to other parties prior to public disclosure. - 25 July 2020 – RedHat contact requests short disclosure date due to public release, Artifex set as 03 August.
- 27 July 2020 – Insomnia Security request package or urgent work-around information for client. Artifex indicate packaged versions will not be produced.
- 27 July 2020 – Artifex publish disclosure ahead of original deadline (again without warning).





