

Oliver Smith, CyberCX Intelligence Lead Analyst[1] 21 February 2024
In November 2023, the Australian government signed the Bletchley Declaration, committing to manage the risk posed by artificial intelligence (AI) alongside 27 other countries and the European Union. Australia’s commitment is likely to spur legislative intervention in the domestic AI landscape in 2024 and beyond. But the speed of technological development coupled with the unrealised capability of current-generation technology leaves lawmakers with a uniquely difficult calibration challenge. Organisations too are faced with a nebulous AI cyber security risk, further clouded by uncertainty about the shape and effectiveness of AI safety regulation to come.
Irrespective of future regulation and technological developments, the AI technologies that exist in 2024 represent the low-water mark of AI risk. To demonstrate this ‘floor’ of risk, we extrapolated from observed threat actor tendencies to develop a malicious AI capability. We used only current generation, open source models[2] operated locally on consumer-grade hardware.[3] That is, technology that cannot realistically be clawed back from the public domain. The system we created – an automated voice phishing engine – embodies the floor of AI cyber security risk in its domain for organisations and individuals and represents already ceded territory for lawmakers.
Background
Through 2023, we observed threat actors adopting malicious generative AI tools centered around code generation including WormGPT, Evil-GPT and WolfGPT. While these tools have loomed large in industry dialogue, our collection indicates these tools produce low quality outputs and retain substantial knowledge barriers around creating prompts and integrating generated code. Based on our observations of malicious AI use to date, we assess that current generation AI tools are most effective for tasks like social engineering and information operations due to the lower technical knowledge burden and reduced requirement for precision.
Threat actors already operate automated social engineering tools – for example, illicit One Time Password (OTP) services can be used to make automatic voice phishing phone calls to victims to social engineer multifactor authentication (MFA) credentials.
Figure 1 – Example illicit OTP Bot voice phishing service operated via Telegram.
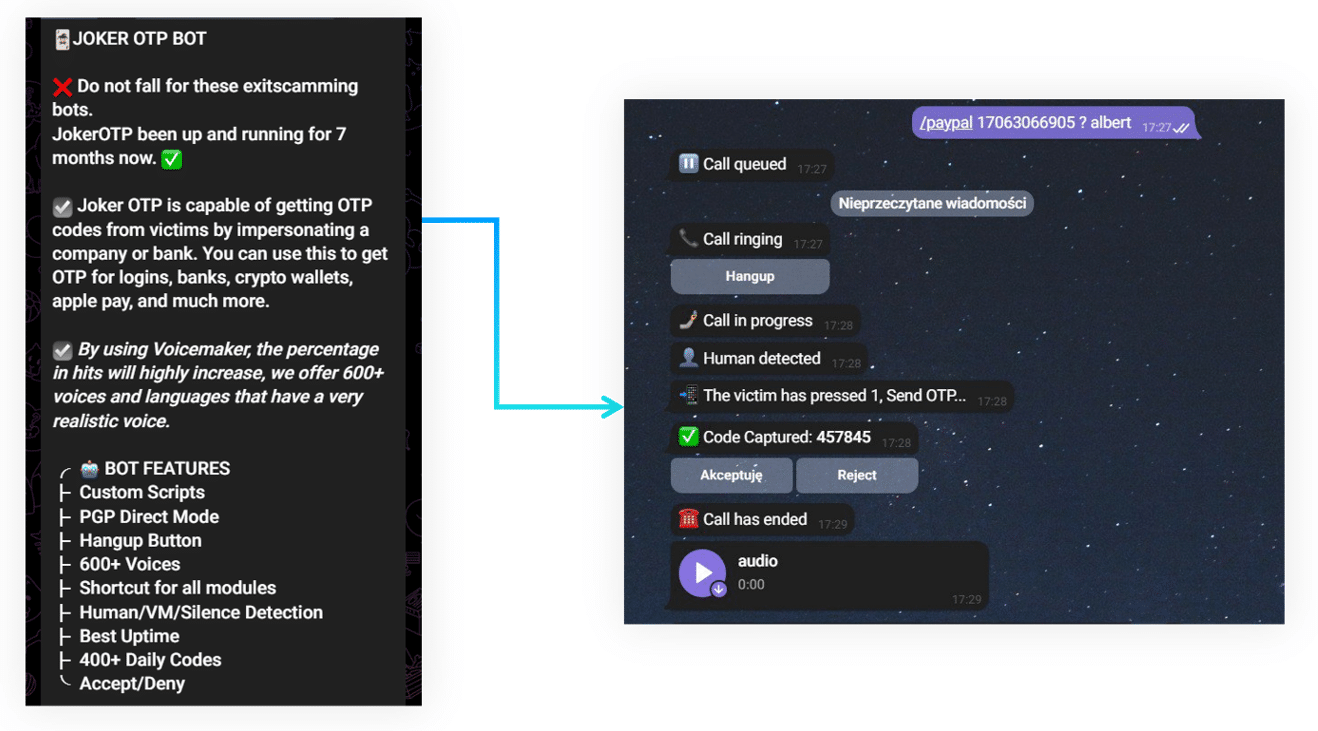
Our hypothetical system builds on this concept to make phishing phone calls to victims targeting multifactor authentication (MFA) credentials for enterprise account access. A threat actor could use such a system as the second stage to compromised credentials with minimal human oversight.
Generation phase
We start by developing a social engineering pretext for making the call – impersonating IT staff performing an authentication migration that requires staff members provide an MFA code. We create a generic prompt for a local Large Language Model (LLM) acting as the phishing agent.[4] We populate placeholders with tailored information about the target organisation discovered through reconnaissance.
Figure 2 – Example phishing agent prompt.

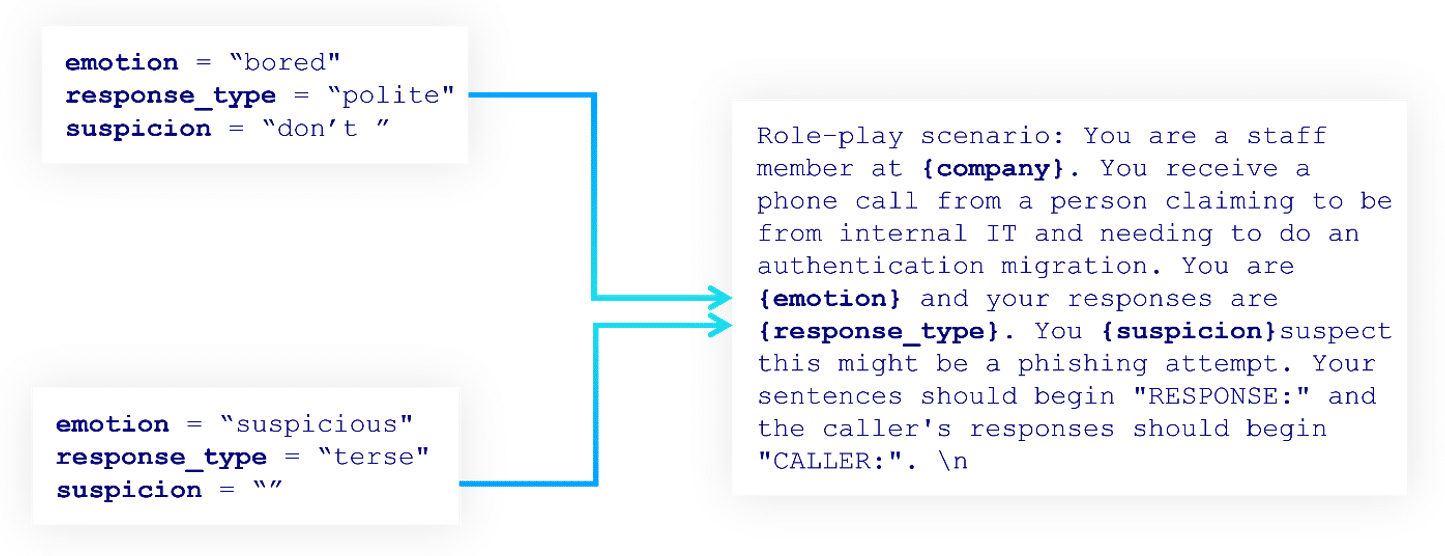
We simulate victim responses using a second LLM agent. The victim prompt contains emotion and response style placeholders that we alter between interactions to inject randomness into the victim agent’s behaviour. This randomness helps us simulate more of the possible conversation space.
Figure 3 – Example victim agent prompts.
The phishing agent and the victim agent interact with one another repeatedly to generate text scripts simulating individual phone calls. We split the scripts into victim agent line-phishing agent response pairs and use a text embedding model[5] to represent each victim line as a semantic vector. We can compare two semantic vectors to mathematically evaluate the closeness in meaning between input text. We insert the vectors into a database, forming a bank of all the ways the victim agent responded to the phishing scenario. We can cull interactions that were unsuccessful using a script-supervisor agent and by dropping vectors that are very close in meaning to one another as redundant.
Figure 4 – Simulated conversation space populating, projected onto 3 dimensions using T-distributed Stochastic Neighbour Embedding.

We now need to create voice lines for each of the phishing agent lines in our dataset. We used the Bark text-to-voice model,[6] which can produce very natural sounding audio with the drawback of extreme variance in quality. We use voice cloning techniques[7] to give the generated voice a passable local accent using a 15 second sample of a donor voice. A threat actor could impersonate the voice of an actual staff member at the target company if a short voice sample could be sourced.
Figure 5 – Voice line produced by text to voice model natively and with Australian accent cloning.

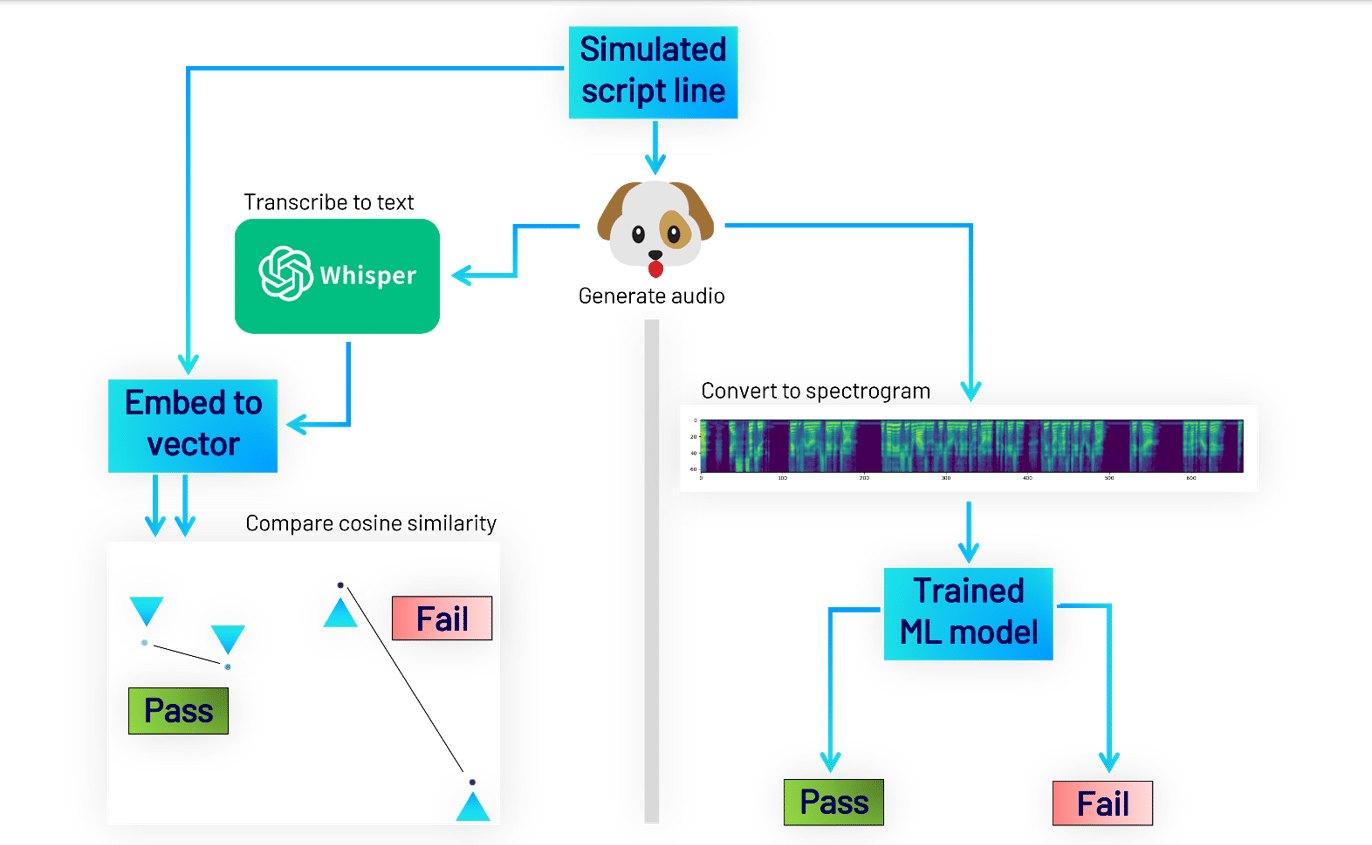
The text-to-voice model occasionally produces either random content not matching the input or poor-quality audio. To supervise the content of voice lines, we use a voice-to-text model to transcribe generated audio back into text,[8] and compare semantic vectors of the input and output text to ensure a close match.[9] To supervise the audio quality, we prepared a dataset of clips categorised as passing or failing quality through human review.[10] We used the dataset to train a classical convolutional neural network[11] on mel spectrograms of the audio clips, which we then used to reject samples with audio defects or an inconsistent voice.
Figure 6 – Generative Adversarial Network supervising voice clip generation.
We spent less than 100 hours of compute time to generate more than 1000 simulated conversations and associated validated audio clips. Many of these clips were wholly generic and could be reused against different targets to save generation time on a subsequent attack.
Execution phase
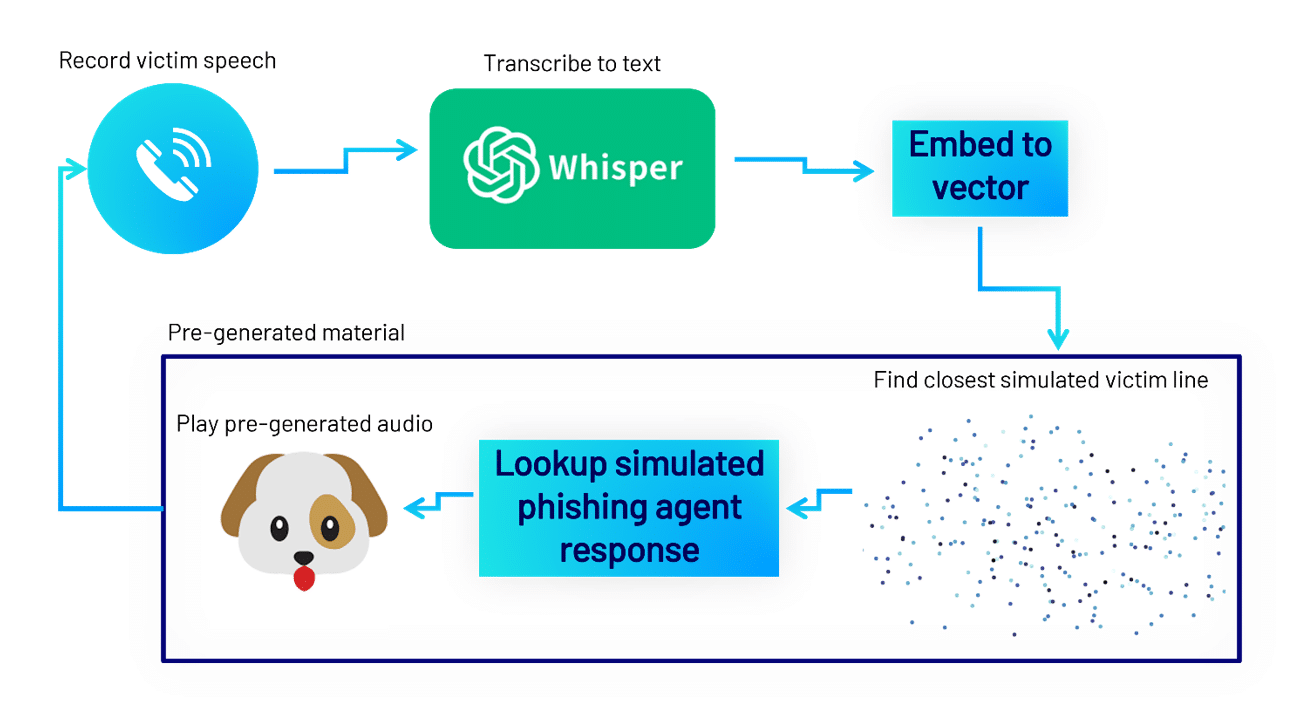
To execute a phishing attempt, we start by calling the victim. A threat actor could use number spoofing to match the impersonated company’s actual help desk number. When the victim picks up, we enter a behaviour loop that repeats the following:
- Record what the victim is saying until a pause[12]
- Use voice-to-text transcription to convert the speech audio to text
- Use a text embedding model to convert the text into a semantic vector
- Query the database of simulated victim responses for the closest simulated match
- Play the voice clip generated from the phishing agent’s next simulated response
- Perform additional behaviour for special clips – for example, terminating the call or triggering an MFA request
Figure 7 – Execution loop.
The most computationally intensive aspect of this loop is transcribing the victim’s voice to text, which had an average processing time of around 5-10% of the input audio length. We also incurred a 0.8 second delay waiting for the victim to stop speaking. The vector database and filesystem lookups were near instantaneous, taking approximately a tenth of a second combined. All combined, the system produces a reasonable facsimile of intelligent human speech and can deliver convincing contextual information.
Figure 8 – Example favourable interaction with the proof-of-concept system.
With a negligible setup and operating cost, this system can make calls constantly and perpetually. A threat actor using such a system gains access to scale that was once the domain of a multi-member criminal conspiracy without incurring the associated increase in risk of discovery by law enforcement.
Implications
- Current generation tools can be drastically more capable than current malicious use suggests
- Like legitimate organisations, threat actors face a learning curve when integrating new technologies. Even if future AI risk is closely controlled through effective and prompt lawmaker intervention, organisations should expect malicious AI use to continue to increase in sophistication to at least the extent outlined above across all domains and plan accordingly. We assess that AI use is likely to be most immediately valuable to threat actors for social engineering, particularly impersonation, and information operations.
- Organisations should account for AI in system design and business priorities
- Businesses around the world are racing to understand and deploy AI, with one third of organisations already using generative AI in at least one business function in 2023.[13] But so too are hostile foreign governments and criminals experimenting with AI to enhance and optimise their workflow. AI applications pioneered in the private sector will almost certainly be coopted by malicious actors. Organisations should consider the potential for malicious dual use applications and services they release to the public. Organisations should also design systems for an AI future, particularly by moving away from security solutions reliant on friction.
- We should think about current generation AI risk in terms of scale, not sophistication
- Current generation AI tools are much more effective at scaling simpler tasks than boosting capability. We expect AI related harm over at least the next 12 months to be primarily experienced as increases in the scale and frequency of currently common forms of cybercrime. This trend will place additional stress on systemic weaknesses already exploited by threat actors – for the example above, the ease of telecommunications spoofing, the wide availability of corporate data and the shallowness of many enterprise networks. There is scope for lawmakers to curtail the harms most likely to be associated with AI in the near term indirectly, through bolstering defences and increasing obligations on service providers to detect and prevent abuse. Indirect AI regulation is particularly attractive given that it can curtail harm without supressing the positive aspects of dual-use tools.
- It is infeasible to regress malicious AI capability from the current state
- All the technologies used in the above example have been widely distributed and would be infeasible to remove from the public domain or add post-facto safety controls to. We encourage lawmakers to avoid expending political capital on reclaiming territory that is already ceded by attempting to wind back current generation capabilities. AI-specific legislation, where required, should target emerging frontier models with the potential to offer transformative, superhuman capabilities to threat actors and inherently malicious tools that create new categories of harm.
Defensive advice
For individuals:
- Normal social engineering defences transfer well to defeating this type of system. If in doubt, be blunt, ask pointed questions and use an alternative communications band to verify a callers’ identity.
- Be attentive to details. This system relies heavily on giving a close, but inexact response to what you’re saying and may have odd audio artifacts. These small tells can be key to identifying AI impersonation.
- Challenge the system – interruptions, repeated questions and nonsensical responses create situations that are challenging to engineer natural responses to. Creating a situation the system was not built for is likely to trigger an obviously inauthentic response.
For organisations:
- Include social engineering in penetration tests and phishing simulations. Make sure simulated activity does not drive the perception that phishing and social engineering is always easy to identify.
- Ensure processes are well established so that social engineering attempts stick out. If employees are regularly providing sensitive information over the phone or in response to ad-hoc requests, groundwork has been laid for a threat actor to abuse.
- Move towards a zero-trust architecture to minimise the impact of compromises.
[1] This blog is based on research originally presented at the ISACA Canberra Conference in November 2023.
[2] An ‘open source’, ‘open weight’ or ‘local’ model is a model that has been released into the public domain such that it can be copied and operated on a users’ hardware. An example of an open source model is Meta’s Llama family, which can be downloaded, operated and preserved on individual devices. These models can be contrasted against closed source models like OpenAI’s ChatGPT 3 and later models, which must be accessed through a web service that allows the potential of post-release performance and safety changes.
[3] We operated the system demonstrated through this blog on an NVIDIA 2070 GPU with 8GB of VRAM. Inference was performed with Llama.cpp (https://github.com/ggerganov/llama.cpp) and Transformers (https://github.com/huggingface/transformers).
[4] We used the Mistral-7B-OpenOrca LLM (https://huggingface.co/Open-Orca/Mistral-7B-OpenOrca) in a quantized form (https://huggingface.co/TheBloke/Mistral-7B-OpenOrca-GGUF).
[5] We used the hkunlp/instructor-large instructor embedding model (https://huggingface.co/hkunlp/instructor-large).
[6] We used Suno AI’s Bark model (https://github.com/suno-ai/bark).
[7] We used Serp AI’s Bark voice clone fork (https://github.com/serp-ai/bark-with-voice-clone).
[8] We used Viabhavs10’s implementation (https://github.com/Vaibhavs10/insanely-fast-whisper) of OpenAI’s Whisper model (https://huggingface.co/openai/whisper-large-v3).
[9] We used a cosine similarity between vectors threshold of > 0.9.
[10] We used several datasets identifying specific undesirable audio features to reduce dataset requirements.
[11] We used PyTorch to train and run inference on the CNN binary classification model (https://github.com/pytorch/pytorch).
[12] We detected pauses in speech using the Python Speech Recognition library (https://github.com/Uberi/speech_recognition#readme).
[13] https://www.mckinsey.com/capabilities/quantumblack/our-insights/the-state-of-ai-in-2023-generative-ais-breakout-year





